

Dimensional modelling (Kimball-style) organizes analytics databases around fact tables (what happened) and dimension tables (the who/what/where/when context). Dimension tables often need specific patterns, either Type 1 SCD (Slowly Changing Dimension) – where changes overwrite the previous value – or Type 2 SCD, where historical changes are preserved with effective-date ranges, and consistent surrogate key generation for stable references across time.
dbt (data build tool) macros excel at these patterns because they’re parameterized, reusable pieces of SQL templating – write the Type 2 SCD logic once as a macro, invoke it against every dimension table with different source and target configurations.
This article walks through the following:
- Type 1 dimension macro – overwrite-in-place pattern for attributes where history isn’t needed;
- Type 2 dimension macro – adding effective_from/effective_to/is_current columns, comparing incoming rows to existing current rows, expiring changed rows and inserting new versions;
- Surrogate key generation via dbt_utils.generate_surrogate_key or MD5 hashing of business key columns;
- dbt test patterns for validating dimension integrity (unique business keys, current-row count per business key, no overlapping effective-date ranges).
Pattern generalizes across Snowflake, BigQuery, Redshift, Databricks, PostgreSQL, and Microsoft Fabric with minor adapter syntax differences.
Introduction
In previous articles we introduced the popular data engineering tool dbt (data build tool). We showed you how you can transform data in a Microsoft Fabric warehouse and how you can create tables with dbt models. We also demonstrated how you can use macros and Jinja to mimic the behavior of dynamic SQL (which we all know and love to use for our scripting), and apply this to create a date dimension.
In this article, we’ll revisit the dimension models we created. We wrote the entire SQL statement for the dimension by hand, and the dimensions themselves were very rudimentary; they lacked a surrogate key and there were no audit columns (such as insert date and update date). We’ll show you how we can expand the dimensions using Jinja, but also how we can minimize development effort by baking reusable patterns into the Jinja code. We’ll focus on loading dimensions of type Slowly Changing Dimension Type 1, which means no history is kept. Type 2 will be the focus of another article.
Load a Type 1 Dimension
Writing the Business Logic
There’s only so much you can abstract away. Every dimension or fact table will have some SQL code that is truly unique for that table: the business logic. Loading a dimension is always the same: check if a row exists by using the business key columns (which define the uniqueness of a dimension member). If it doesn’t exist yet, insert a new row. If it does exist, check if the row needs to be updated or not; if it does, update it. However, defining the expressions that define each column is something we cannot generate. No matter which tool, framework or scripting you use, there will always be work that you need to do for each table. We are going to put that unique part into a view.
Let’s look at the Product dimension we created in the previous article:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
WITH cte_categories AS ( SELECT ProductCategoryID ,ProductCategoryName = [Name] FROM {{ source('adventureworkslt', 'ProductCategory') }} WHERE ParentProductCategoryID IS NULL ) , cte_subcategories AS ( SELECT ProductSubCategoryID = sc.ProductCategoryID ,ProductSubCategoryName = sc.[Name] ,c.ProductCategoryName FROM {{ source('adventureworkslt', 'ProductCategory') }} sc LEFT JOIN cte_categories c ON sc.ParentProductCategoryID = c.ProductCategoryID WHERE ParentProductCategoryID IS NOT NULL ) , cte_models AS ( SELECT m.ProductModelID ,ProductModelName = m.[Name] ,ProductModelDesc = ISNULL(d.[Description],'Description missing...') FROM {{ source('adventureworkslt', 'ProductModel') }} m LEFT JOIN {{ source('adventureworkslt', 'ProductModelProductDescription') }} md ON m.ProductModelID = md.ProductModelID AND md.Culture = 'en' LEFT JOIN {{ source('adventureworkslt', 'ProductDescription') }} d ON md.ProductDescriptionID = d.ProductDescriptionID ) SELECT p.ProductID ,ProductName = p.[Name] ,p.ProductNumber ,ProductColor = ISNULL(p.Color,'N/A') ,p.StandardCost ,p.ListPrice ,ProductSize = ISNULL(p.Size,'N/A') ,ProductWeight = p.[Weight] ,p.SellStartDate ,p.SellEndDate ,p.DiscontinuedDate ,ProductSubCategoryName = ISNULL(pc.ProductSubCategoryName,'N/A') ,ProductCategoryName = ISNULL(pc.ProductCategoryName,'N/A') ,ProductModelName = ISNULL(m.ProductModelName,'N/A') ,ProductModelDesc = ISNULL(m.ProductModelDesc,'N/A') FROM {{ source('adventureworkslt', 'Product') }} p LEFT JOIN cte_subcategories pc ON p.ProductCategoryID = pc.ProductSubCategoryID LEFT JOIN cte_models m ON p.ProductModelID = m.ProductModelID; |
This query defines the business logic used for this dimension. When we run this model, it will create a table called DimProduct, but as mentioned before we are missing some columns like the surrogate key. We can add them to this model, or we can create a reusable template for a dimension to minimize development time and especially reduce the risk for mistakes. Another advantage is that all our dimensions will be standardized in format and naming conventions.
The first step is to transform this model into a view. We can do this by simply adding the following Jinja configuration at the top of the model:
|
1 2 3 4 5 |
{{ config( materialized = 'view' ) }} |
We also rename the model to vw_Dimproduct.sql:
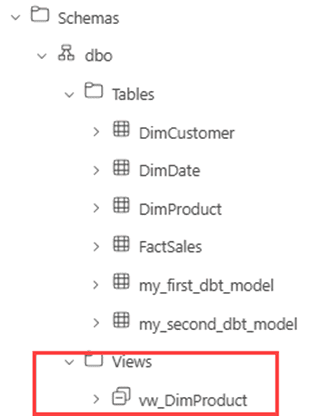
When we now build the model, we can see a view will be created in our Fabric warehouse:
Create the Dimension Model with Jinja
With the following model, we can load our dimension table:
|
1 2 3 4 5 6 7 8 9 10 11 |
{%- set columns = adapter.get_columns_in_relation(ref('vw_DimProduct')) -%} {#- Define the business key columns -#} {%- set bk_cols = ['ProductID'] -%} SELECT SK_Product = {{ dbt_utils.generate_surrogate_key(bk_cols) }} {% for col in columns -%} ,{{col.column}} {% endfor -%} ,InsertDate = SYSDATETIME() ,UpdateDate = SYSDATETIME() FROM {{ ref('vw_DimProduct') }} |
It generates the following SQL code:
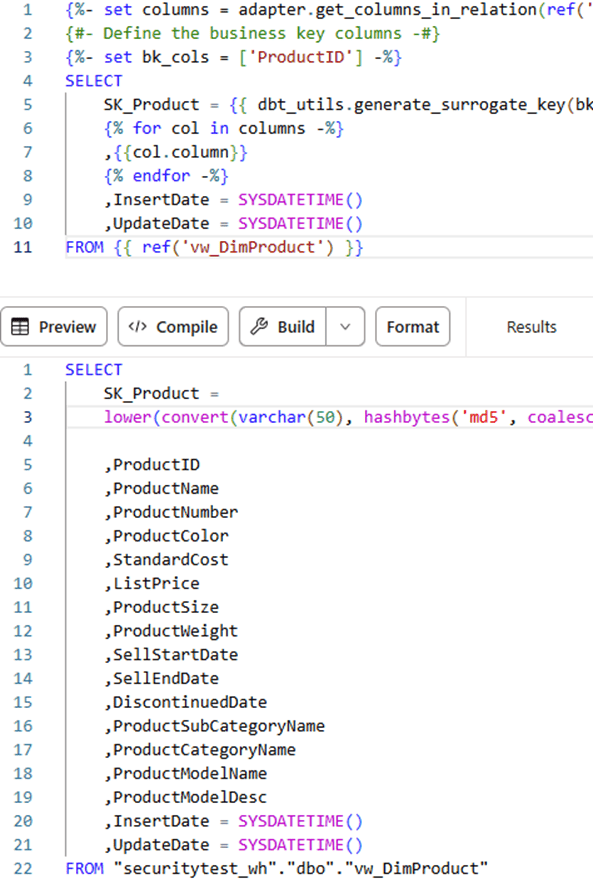
Let’s take a closer look at what happens in this script. We don’t want to write out all of the different columns, so the macro get_columns_in_relation from the dbt adapter object is used to fetch all the columns from the view we reference. Using a for loop, we can loop over this collection and write out all the column names in the SELECT statement.
As mentioned before, we also want to generate a surrogate key. Traditionally, this is done by using an IDENTITY constraint in SQL Server, since surrogate keys are defined as meaningless integers. In dbt however, there are two problems with this approach:
- Since you don’t specify an
IDENTITYcolumn in yourSELECTstatement (because it is auto-populated), it’s not supported in dbt. If it isn’t specified in the model, the column doesn’t exist for dbt, since dbt creates tables by wrapping theSELECTstatement in aCREATE TABLE AS SELECTstatement. Furthermore, at the time of writing, the Fabric Warehouse doesn’t supportIDENTITYconstraints yet. - We could work around this by generating the surrogate keys ourselves (for example by using the
ROW_NUMBERfunction), but this goes against the principle of dbt, where models should be idempotent; if you drop a table and run the model again, you should get the same result.
To solve these issues, typically hashes are used in dbt for the surrogate keys. There are interesting discussions online of the benefits here and here. One of the advantages of using a hash is that you can drop and reload your dimensions without having the reload your fact tables. Coming from a SQL Server world, the approach of using hashes might seem strange and unusual and it can take some time to get used to.
We can generate a hash-based surrogate key using the generate_surrogate_key macro from the dbt_utils package. It needs the business keys of the dimension as input, so they are defined at the start of the model as an array variable:
|
1 2 |
{#- Define the business key columns -#} {%- set bk_cols = ['ProductID'] -%} |
The first line of the script above shows how you can put comments in your Jinja code. You might’ve also noticed the minus signs here and there at the start or end of the Jinja code. These are used to control white space. If for example we remove them from this block:
|
1 |
{% for col in columns -%} |
…we get the following result:
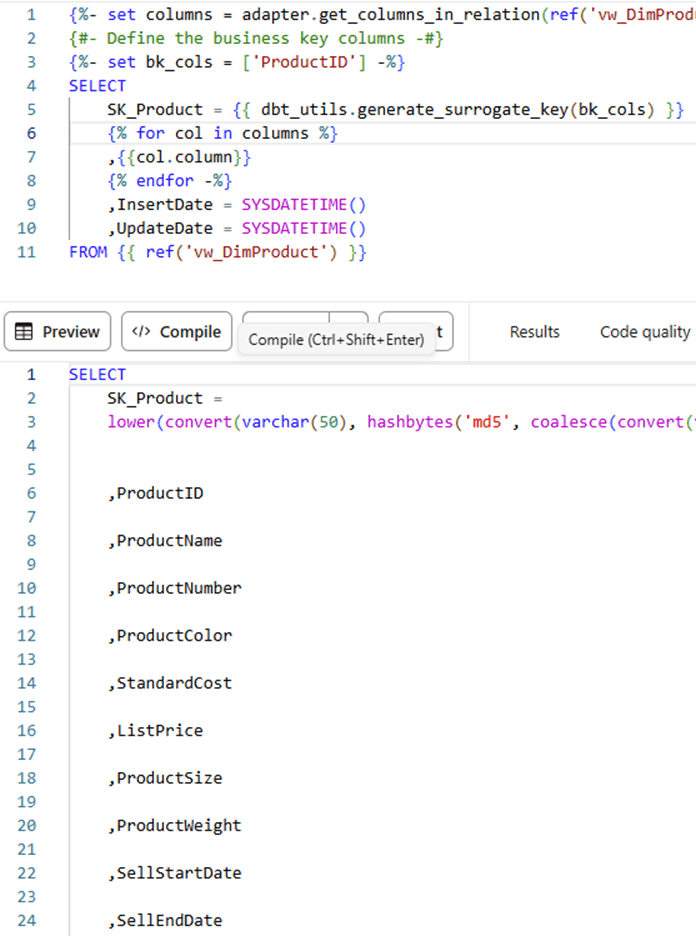
It can be trial & error to get the correct white space control, but the focus should be on writing readable model code, not necessarily nicely formatted generated SQL.
If we now build the model, we get the dimension we need:
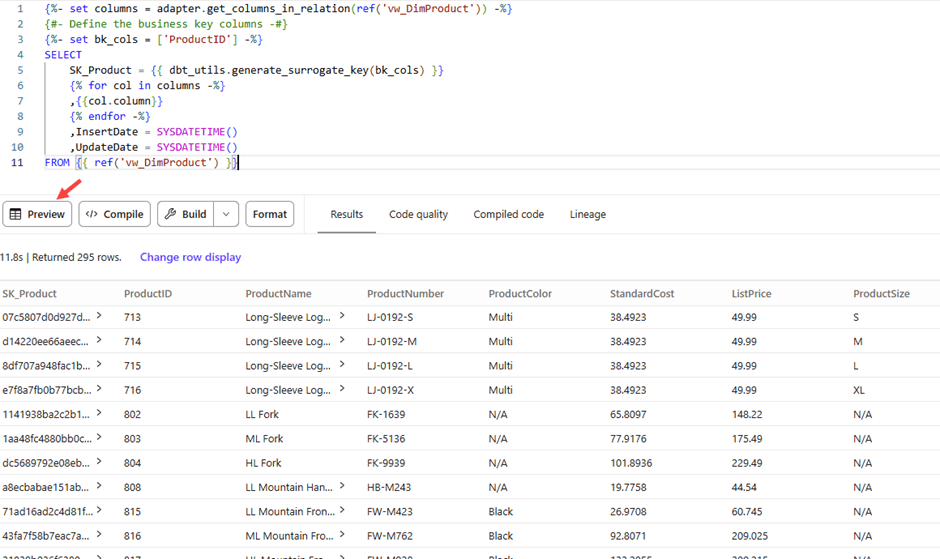
This model will drop the dimension table and recreate it fully when the model is run. Because of the hashed surrogate key and because we don’t need to track history, this shouldn’t be an issue.
Optimizing the Jinja
We still must specify the reference to the vw_DimProduct view twice, and specify a custom name for the surrogate key. It’s not that big of a deal, but when you copy-paste this code for another dimension and forget to adapt something, you might end up with a customer dimension with SK_Product for its surrogate key name. So let’s modify the Jinja so we only need to specify the dimension name once, and the Jinja code takes care of the rest:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
{%- set dimname = 'Product' -%} {%- set relname = 'vw_Dim' + dimname -%} {%- set columns = adapter.get_columns_in_relation(ref(relname)) -%} {#- Define the business key columns -#} {%- set bk_cols = ['ProductID'] -%} SELECT {{ 'SK_' + dimname }} = {{ dbt_utils.generate_surrogate_key(bk_cols) }} {%- for col in columns -%} ,{{col.column}} {% endfor -%} ,InsertDate = SYSDATETIME() ,UpdateDate = SYSDATETIME() FROM {{ ref(relname) }} |
By using a naming convention for the view and the surrogate key (vw_DimMyDimension and SK_MyDimension), we only need to write the dimension name once and insert it where needed. Keep in mind we still need to specify the business key columns.
We can go one step further, and turn the script into a macro, maximizing the reusability. Let’s add a new file to the macros folder:
We’re going to name the macro load_dimension.
The macro itself contains the following code:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
{% macro load_dimension(dimension_name, bk_columns) %} {%- set relname = 'vw_Dim' + dimension_name -%} {%- set columns = adapter.get_columns_in_relation(ref(relname)) -%} SELECT {{ 'SK_' + dimension_name }} = {{ dbt_utils.generate_surrogate_key(bk_columns) }} {%- for col in columns -%} ,{{col.column}} {% endfor -%} ,InsertDate = SYSDATETIME() ,UpdateDate = SYSDATETIME() FROM {{ ref(relname) }} {% endmacro %} |
The SQL code in the DimProduct.sql file simply becomes:
|
1 |
{{ load_dimension('Product',['ProductID']) }} |
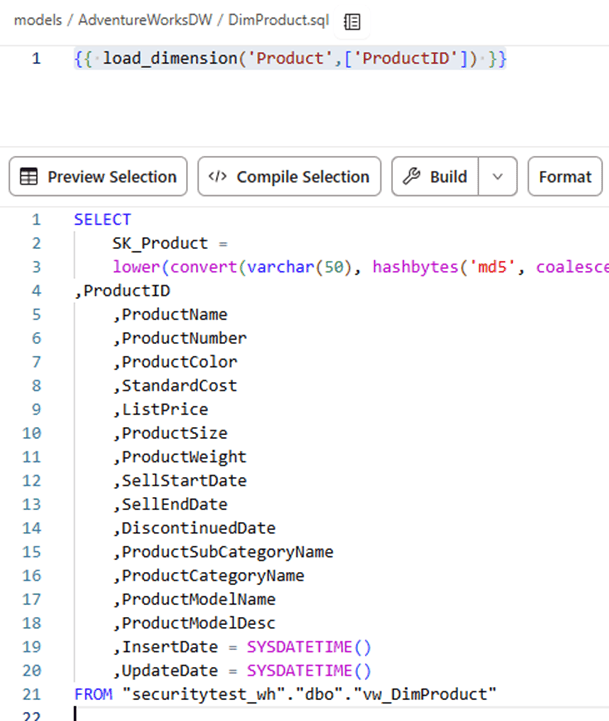
If your dimension has multiple columns for the business key, then you can pass them along in array-format:
|
1 |
{{ load_dimension(MyDimension,['BK_Column1', 'BK_Column2']) }} |
As an exercise for the reader, try to convert the model for the customer dimension to a model where you only use this macro.
Conclusion
In this article, we put the business logic – which is unique for every table – in a view and then used Jinja to abstract all the other logic, such as creating a surrogate key and audit columns, away. dbt and macros are all about reusability of code and trying to implement patterns. In the end, we went as far as creating a macro for our pattern and the dimension model only consists of one single line of Jinja code that calls the macro.
By using macros and Jinja, we can standardize the models in our dbt project and minimize the risk of errors.





Load comments